Modeling and Simulating Social Media in Python
Sentiment Analysis of Social Media with Python
Beginner-friendly overview of Python tools available for classifying sentiment in social media text. I discuss my experiences using different tools and offering suggestions to get y'all started on your ain Python sentiment analysis journey!
In ancient Rome, public discourse happened at the Forum at the eye of the city. People gathered to substitution ideas and argue topics of social relevance. Today that public discourse has moved online to the digital forums of sites like Reddit, the microblogging arena of Twitter and other social media outlets. Perhaps every bit a researcher you are curious what people'south opinions are about a specific topic, or perhaps as an analyst yous wish to study the upshot of your visitor'south recent marketing campaign. Monitoring social media with sentiment analysis is a good mode to gauge public opinion. Luckily, with Python there are many options available, and I will discuss the methods and tools I have experimented with, along with my thoughts virtually the experience.
On my learning journey, I started with the simplest selection, TextBlob, and worked my fashion up to using transformers for deep learning with Pytorch and Tensorflow. If you lot are a beginner to Python and sentiment analysis, don't worry, the next department provides background. Otherwise, feel free to skip alee to my diagram beneath for a visual overview of the Python tongue processing (NLP) playground.
Introduction to Sentiment Analysis
Sentiment analysis is a part of NLP; text can be classified by sentiment (sometimes referred to as polarity), at a coarse or fine-grained level of analysis. Coarse sentiment analysis could be either binary (positive or negative) nomenclature or on a 3-bespeak calibration which would include neutral. Whereas a 5-bespeak scale would exist fine-grained analysis, representing highly positive, positive, neutral, negative and highly negative. Early analysis relied on rule-based methods, similar those used by the Python libraries TextBlob and NLTK-VADER, both of which are popular amongst beginners. Most machine learning (ML) methods are feature-based and involve either shallow or deep learning. Shallow approaches include using nomenclature algorithms in a single layer neural network whereas deep learning for NLP necessitates multiple layers in a neural network. One of these layers (the first hidden layer) will be an embedding layer, which contains contextual information.
A detailed caption of neural nets is beyond the scope of this mail service, however for our purposes an oversimplification will suffice: Neural networks are a drove of algorithms that learn relationships near data in a way that mimics the network of neurons in the man brain. For a deeper swoop into the fascinating theory behind neural networks, I suggest this introductory mail.
A common theme I noticed is that the better a method is at capturing nuances from context, the greater the sentiment classification accurateness. There are several techniques for encoding or embedding text in a way that captures context for higher accurateness. Therefore an embedding layer is integral to the success of a deep learning model. Today, deep learning is advancing the NLP field at an exciting rate. At the cut edge of deep learning are transformers, pre-trained language models with potentially billions of parameters, that are open-source and can be used for state-of-the-art accuracy scores. I created the diagram below to showcase the Python libraries and ML frameworks available for sentiment analysis, just don't feel overwhelmed there are several options that are attainable for beginners.
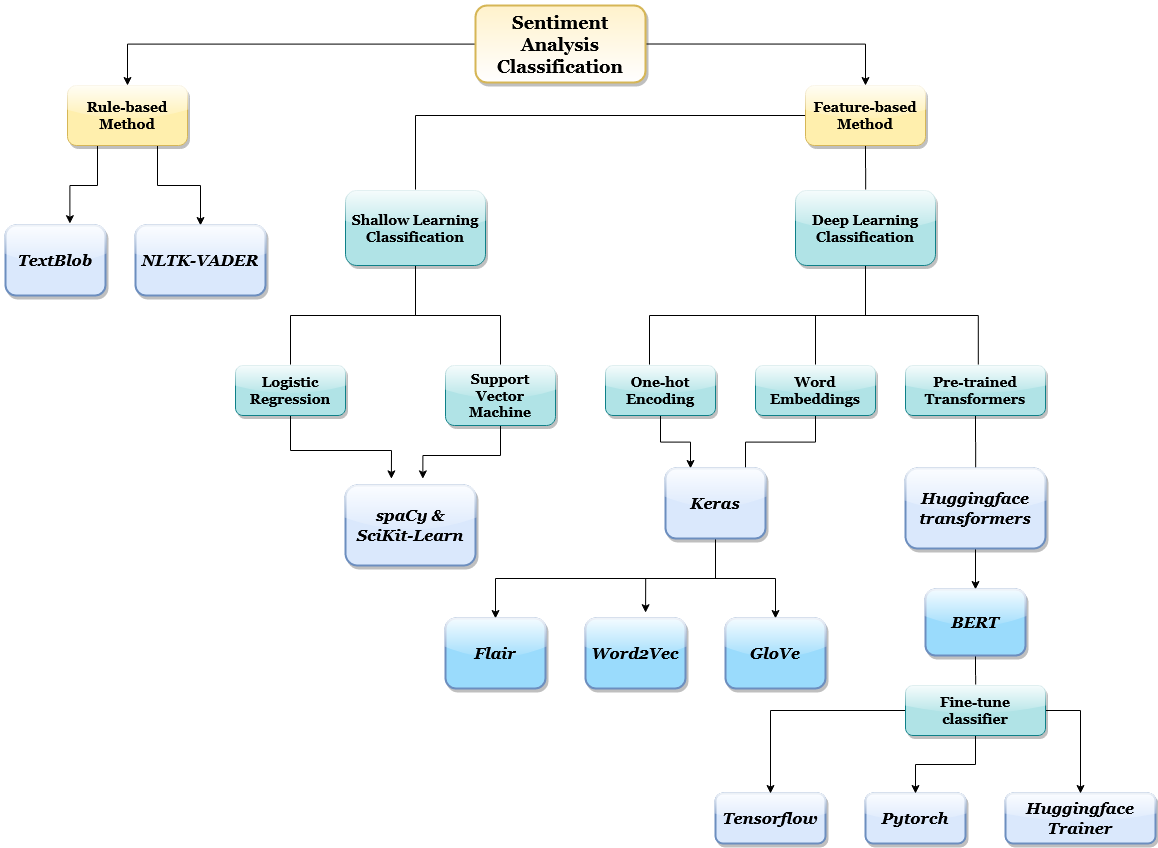
Rule-based Python Libraries
TextBlob is pop considering information technology is uncomplicated to use, and it is a good place to start if you are new to Python. An early project of mine involved information visualization of polarity and subjectivity scores calculated with TextBlob. The lawmaking snippet below shows a straightforward implementation of TextBlob on tweets streamed from Twitter in real-time, for the full lawmaking check out my gist.
While using TextBlob is easy, unfortunately it is non very accurate, since natural language, especially social media language, is complex and the nuance of context is missed with dominion based methods. NLTK-VADER is an NLP package developed specifically for processing social media text. I propose checking it out if yous are working with tweets and looking for a betoken of comparison for TextBlob.
Machine Learning for Feature-based Methods
I realized that if I wanted greater accuracy, I needed to employ machine learning; contextualization was central. I started with conventional shallow learning approaches like logistic regression and support vector car algorithms used in single layer neural nets. Likewise requiring less piece of work than deep learning, the advantage is in extracting features automatically from raw data with little or no preprocessing. I used the NLP package spaCy in combination with the ML package scikit-acquire to run simple experiments. I was inspired by a blog post, where the writer used these 2 packages to detect insults in social commentary to identify bullies. For fine-grained sentiment classification, car learning (characteristic-based) has an advantage over rule based methods, this splendid post compares the accuracy of rule based methods to feature based methods on the 5-class Stanford Sentiment Treebank (SST-5) dataset.
Deep Learning: Embeddings and Transformers
Deep learning and discussion embeddings farther improved accuracy scores for sentiment analysis. In 2013, Google created the Word2Vec embedding algorithm, which along with the GloVe algorithm remains the 2 well-nigh popular word embedding methods. For a practical walk-through, check out this mail, where the author uses embeddings to create a book recommendation system. Traditionally, for deep learning classification a word embedding would exist used as part of a recurrent or convolutional neural network. Nonetheless, these networks take a very long time to train, because with recurrence and convolutions it is difficult to parallelize. Attention mechanisms improved the accurateness of these networks, then in 2017 the transformer compages introduced a way to use attention mechanisms without recurrence or convolutions. Therefore, the biggest evolution in deep learning for NLP in the by couple years is undoubtedly the advent of transformers.
Python Deep Learning Libraries
When I started studying deep learning, I relied on Reddit recommendations to option a Python framework to start with. The top suggestion for beginners was the Python library, Keras, which works as a functional API. I found it very accessible, peculiarly since it is built on pinnacle of the Tensorflow framework with enough brainchild that the details do non become overwhelming, and straightforward enough that a beginner can learn by playing with the code. Simply because Keras simplifies deep learning, this does not mean that information technology is ill-equipped to handle circuitous problems in a sophisticated way. It is relatively piece of cake to augment Keras with Tensorflow tools when necessary to tweak details at a low level of brainchild, therefore Keras is a capable competitor on the deep-learning battlefield. In the lawmaking snippet below I was attempting to build a classifier from a pre-trained linguistic communication model while experimenting with multi-sample dropout and stratified k-fold cross-validation, all of which was possible with Keras.
My introduction to transformers was the adorably named Python library, Huggingface transformers. This library makes information technology simple to use transformers with the major machine learning frameworks, TensorFlow and Pytorch, as well as offering their own Huggingface Trainer to fine-tune the assortment of pre-trained models they make available. The most popular transformer BERT, is a language model pre-trained on a huge corpus; the base of operations model has 110 1000000 parameters and the large model has 340 million parameters. For sentiment classification, BERT has to be fine-tuned with a sentiment-labeled dataset on a downstream classification task. This is referred to as transfer learning, which leverages the power of pre-trained model weights that allow for the nuances of contextual embedding to be transferred during the fine-tuning process. At that place are several other transformers such as RoBERTa, ALBERT and ELECTRA, to proper name a few. In add-on to being very accessible, Huggingface has splendid documentation if you are interested in exploring the other models, linked here. Additionally, since fine-tuning takes fourth dimension on CPUs, I suggest taking advantage of Colab notebooks, which volition permit you to run experiments for free on Google'southward deject GPUs (there is a monthly rate limit) for a faster training time.
Which Machine learning framework is right for you?
I can offer my stance on which motorcar learning framework I prefer based on my experiences, but my suggestion is to effort them all at least once. The OG framework Tensorflow is an excellent ML framework, even so I generally use either the Pytorch framework (expressive, very fast, and complete control) or the HF Trainer (direct-forwards, fast, and uncomplicated) for my NLP transformers experiments. My preference for Pytorch is due to the command it allows in designing and tinkering with an experiment — and it is faster than Keras. If you prefer object oriented programming over functional, I suggest the Pytorch framework since the lawmaking makes use of classes, and consequently is elegant and clear. In the code snippet below using Pytorch, I create a classifier course and use a constructor to create an object from the class, which is then executed by the class' forward pass method.
Additional lawmaking is needed to run a backwards pass, and use an optimizer to compute loss and update the weights. The code for Pytorch is significantly longer than the lawmaking required for Keras. If y'all adopt to write code quickly and non spell out every training step, then Keras is a better option for y'all. However, if you lot want to empathise everything that happens during preparation, Pytorch makes this possible. For a step-by-pace guide to Pytorch with examples, check out this introductory mail service. For a absurd project with Pytorch, I recommend this dandy tutorial by Venelin Valkov, where he shows y'all how to employ BERT with Huggingface transformers and Pytorch, and so deploy that model with FASTAPI.
Hopefully this postal service shed some light on where to offset for sentiment analysis with Python, and what your options are every bit you progress. Personally, I await forwards to learning more than virtually recent advancements in NLP and so that I can better utilise the amazing Python tools bachelor.
Belum ada Komentar untuk "Modeling and Simulating Social Media in Python"
Posting Komentar